

蓝狮动态
咨询热线
400-123-4657QQ:1234567890
传真:+86-123-4567
邮箱:admin@youweb.com
性能优化的艺术与实践(一)——高性能JSON解析器
在大规模分布式系统中,一份数据往往需要经过多个流程进行加工处理,考虑到每个流程都会使用各自的编程语言,JSON作为通讯协议是一个理想的选择。
目前常用的JSON解析器中,以RapidJSON的综合性能最好——Benchmark。但是,在特定的应用场景中,还有优化空间。为了降低系统的耦合度,每个流程只处理自己相关的部分即可,JSON解析器只需要完全解析相关部分即可,分析发现,解析数字,最为耗时,因此,在真正使用时才根据精度要求,进行解析能够大幅提高性能。典型的流程图如下:
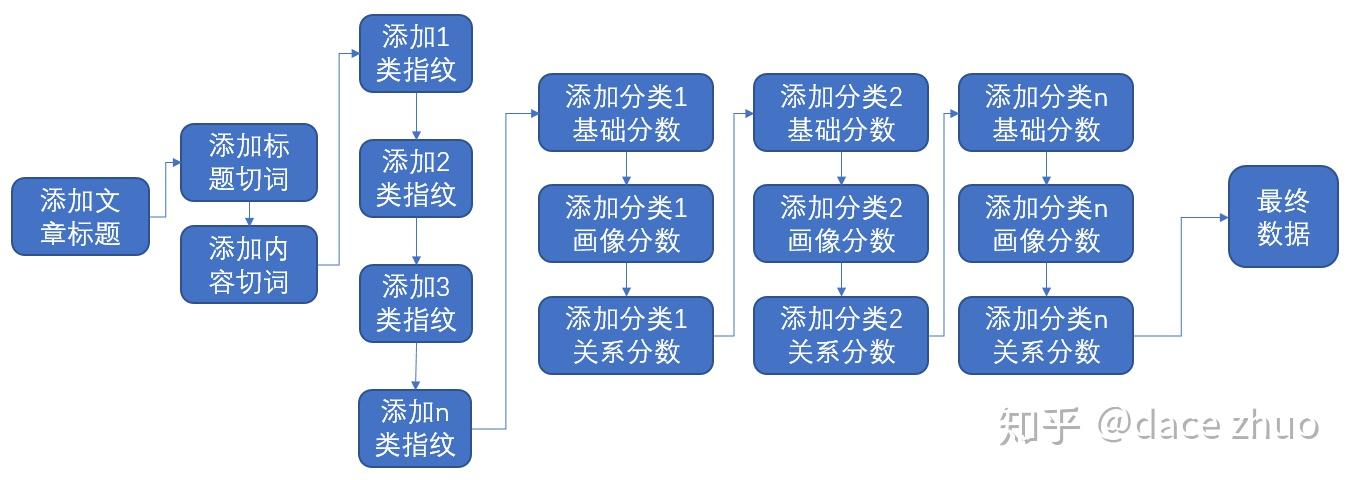
上文提到的JSON解析器被命名为zzzJSON,下文将使用该命名代替。
除了极快的解析和反解析速度外,在实际使用中zzzJSON还必须满足以下要求:
- 实现JSON标准
- 对JSON中的每个值进行增删改查操作
- 保留所有精度供科学计算使用
- 简单易懂
- 能够在多种语言中使用
- 平台无关
本章节描述zzzJSON的实现,包括选择该实现方法的理由以及实现方法。
zzzJSON使用纯C实现,主要是为了满足简单易懂、多种语言中使用以及平台无关的要求。
简单易懂
虽然zzzJSON提供的详细的API说明,但是在极少的情况下也是需要了解实现的细节,从而写出更高效的代码。
考虑到绝大部分计算机专业的毕业生都学过C语言,因此,其具有最广泛的群众基础,因此,zzzJSON选择纯C实现。
zzzJSON为了实现简单易懂还通过以下两种方式:
- 使用最朴素的C代码实现,不带任何花俏的技巧
- 丰富的注释
多语言
要在C、C++、Go、Python、Java、Rust、Scala等多种语言中使用,纯C实现一个JSON解析器是理想的选择,C++完全兼容C,其它语言也能高效地跟C进行交互,下面以Go为例,描述使用纯C实现的优势,代码如下:
package zzzjson
/*
#cgo CFLAGS: -Wall -O3
#define zzz_SHORT_API 0
#include "zzzjson.h"
*/
import (
"C"
)
const (
zzzTrue=C.zzz_BOOL(1)
zzzFalse=C.zzz_BOOL(0)
)
/*
Value JSON Value, it can be one of 6 jsontypes
*/
type Value struct{
V *C.struct_zzz_Value
}
/*
Parse Parse JSON text to value
*/
func (v *Value) Parse(s string) bool{
ret :=C.zzz_ValueParseFast(v.V, C.CString(s))
if ret !=zzzTrue{
return false
}
return true
}
/*
Stringify Stringify Vaue to JSON text
*/
func (v *Value) Stringify() *string{
ret :=C.zzz_ValueStringify(v.V)
if ret==nil{
return nil
}
retStr :=C.GoString(ret)
return &retStr
}从上述代码可以看出,由于使用纯C实现,JSON解析器几乎完美地嵌入Go代码中。
平台无关
考虑到zzzJSON需要在多种环境下运行,减轻运维部署负担,仅仅依赖libc是理想的选择。
内存分配一般是使用malloc函数,该函数极其复杂,包含了锁、用户态到内核态切换和内存映射等复杂的操作,非常慢,因此,提高内存分配速度需要尽量减少malloc函数的调用,为达到该目的,需要实现一个内存分配器,该内存分配器需要满足以下要求:
- 减少malloc的调用次数
- 无锁
- 统一释放
zzzJSON的内存分配器统一管理所有内存操作,它会先使用malloc函数分配一段大小为A的内存,当zzzJSON需要分配内存时,先从该段内存分配,如果使用完,则再使用malloc函数分配一段大小为2A的内存,如此反复。zzzJSON整个生命周期完毕之后,使用free函数,释放所有使用malloc函数申请的内存。内存分配器的结构图如下:
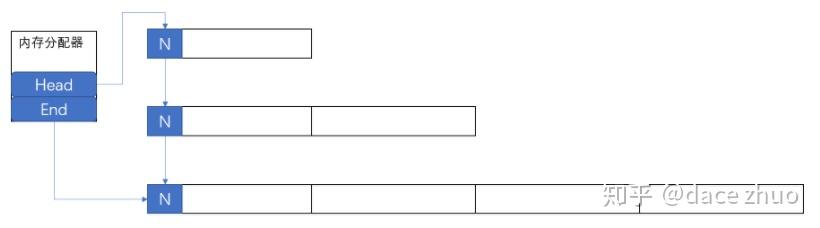
内存分配器的数据结构如下:
// 内存分配器节点
struct zzz_ANode
{
// 数据地址
char *Data;
// 数据大小
zzz_SIZE Size;
// 使用到的位置
zzz_SIZE Pos;
// 下一个节点
struct zzz_ANode *Next;
};
// 内存分配器
// 内存分配器为由内存分配器节点组成的链表,Root为根节点,End总是指向最后一个节点
struct zzz_Allocator
{
// 根节点
struct zzz_ANode *Root;
// 最后一个节点
struct zzz_ANode *End;
};初始化代码如下,值得注意的是分配内存的时候把节点占用的内存也一起分配了:
static inline struct zzz_Allocator *zzz_AllocatorNew()
{
// 分配大块内存
void *ptr=zzz_New(sizeof(struct zzz_Allocator) + sizeof(struct zzz_ANode) + zzz_AllocatorInitMemSize);
struct zzz_Allocator *alloc=(struct zzz_Allocator *)ptr;
alloc->Root=(struct zzz_ANode *)((char *)ptr + sizeof(struct zzz_Allocator));
alloc->End=alloc->Root;
alloc->Root->Size=zzz_AllocatorInitMemSize;
alloc->Root->Data=(char *)ptr + sizeof(struct zzz_Allocator) + sizeof(struct zzz_ANode);
alloc->Root->Pos=0;
alloc->Root->Next=0;
return alloc;
}统一释放内存比单独释放内存效率要高得多,而且可以做到异步释放,即另起一个线程专门做释放内存之用,最大限度地提高性能,这点在下一篇文章中详细描述,代码如下:
static inline void zzz_AllocatorRelease(struct zzz_Allocator *alloc)
{
// 遍历整个链表,每次释放一块内存
struct zzz_ANode *next=alloc->Root->Next;
while (zzz_LIKELY(next !=0))
{
struct zzz_ANode *nn=next->Next;
zzz_Free((void *)next);
next=nn;
}
// 最后释放第一块内存
zzz_Free((void *)alloc);
}分配内存时,如果发现内存不够,则使用malloc函数分配新的内存,代码如下:
// 追加一个大小为 init_size 的节点。
static inline void zzz_AllocatorAppendChild(zzz_SIZE init_size, struct zzz_Allocator *alloc)
{
// 每次分配一大块内存,避免多次分配
void *ptr=zzz_New(sizeof(struct zzz_ANode) + init_size);
struct zzz_ANode *node=(struct zzz_ANode *)ptr;
node->Size=init_size;
node->Data=(char *)ptr + sizeof(struct zzz_ANode);
node->Pos=0;
node->Next=0;
// 在ANode组成的链表最后加一个ANode
alloc->End->Next=node;
alloc->End=node;
return;
}
// 分配大小为size的内存
static inline char *zzz_AllocatorAlloc(struct zzz_Allocator *alloc, zzz_SIZE size)
{
struct zzz_ANode *cur_node=alloc->End;
zzz_SIZE s=cur_node->Size;
if (zzz_UNLIKELY(cur_node->Pos + size > s))
{
s *=zzz_Delta;
// 通过循环计算最终需要的空间大小
// 这里应该有更好的方法,就是直接通过计算所得
while (zzz_UNLIKELY(size > s))
s *=zzz_Delta; // 每次分配内存的大小是上次的zzz_Delta倍
zzz_AllocatorAppendChild(s, alloc);
cur_node=alloc->End;
}
char *ret=cur_node->Data + cur_node->Pos;
cur_node->Pos +=size;
return ret;
}由于zzzJSON的内存分配器无锁,因此,zzzJSON的内存分配器不支持多线程操作。如果需要支持多线程操作,则需要每个线程一个分配器。
递归能够简化代码,但是其效率低下,zzzJSON为了提高性能,采用循环代替所有递归。大部分JSON解析器都是使用递归实现,zzzJSON使用循环实现,同时为了提高增删改查的效率,其内存中的节点使用了比较复杂的数据结构。zzzJSON的节点结构图如下:

如果节点的类型对象或者数组,那么值为其第一个孩子节点。具体的代码如下:
// zzzJSON把文本转化成内存中的一棵树,zzz_Node为该数的节点,每个节点对应一个值
struct zzz_Node
{
// 节点代表的值的类型
char Type;
// 节点代表的值的关键字
const char *Key;
// 节点代表的值的关键字长度
zzz_SIZE KeyLen;
union{
// 如果节点代表的值的类型为数组或者对象,则表示数组或者对象的第一个值对应的节点
struct zzz_Node *Node;
// 如果节点代表的值的类型为字符串,数字,布尔值,则对应其字符串
const char *Str;
}Value;
// 节点对应的值包含值的个数,如果类型非对象或者数组,则为0
zzz_SIZE Len;
// 下一个节点
struct zzz_Node *Next;
// 上一个节点
struct zzz_Node *Prev;
// 父节点
struct zzz_Node *Father;
// 最后一个节点
struct zzz_Node *End;
};以上数据结构是为了实现零递归设计的,下面详细描述零递归解析JSON文本的过程。由于代码比较长,所以只解释关键部分,详细代码请查看代码源文件,关键思路是根据首字符判断值的类型,然后验证值是否符合要求,最后根据下一个字符判断是添加兄弟节点还是向上回溯,关键代码如下:
// 快速解析JSON文本
static inline zzz_BOOL zzz_ValueParseFast(struct zzz_Value *v, const char *s)
{
struct zzz_Node *node=v->N;
// 获得跳过空格、换行等字符获得第一个字符
char c=zzz_Peek(s, &index);
// 以下代码主要是为了解析根节点,减少分支
// 如果把以下代码集合到循环里面,这会造成每次循环都要判断一次是否是根节点
switch (c)
{
case '[':
{
// 设置节点的类型为数组
node->Type=zzz_JSONTYPEARRAY;
// 新建一个节点
zzz_Node *n=zzz_AllocatorAlloc(v->A, sizeof(struct zzz_Node));
// 把当前数组节点的第一个孩子指向n
node->Value.Node=n;
// 当前节点变成n
node=n;
break;
}
case '{':
{
// 设置节点的类型为对象
node->Type=zzz_JSONTYPEOBJECT;
// 新建一个节点
struct zzz_Node *n=zzz_AllocatorAlloc(v->A, sizeof(struct zzz_Node));
// 把当前对象节点的第一个孩子指向n
node->Value.Node=n;
// 当前节点变成n
node=n;
break;
}
case 'n':
// 判断null是否符合预期,并且设置当前节点为null
if (zzz_LIKELY(zzz_ConsumeNull(s, &index)))
break;
case 'f':
// 判断false是否符合预期,并且设置当前节点为false
if (zzz_LIKELY(zzz_ConsumeFalse(s, &index)))
break;
case 't':
// 判断true是否符合预期,并且设置当前节点为true
if (zzz_LIKELY(zzz_ConsumeTrue(s, &index)))
break;
case '"':
// 判断字符串是否符合预期,并且设置当前节点为字符串
if (zzz_LIKELY(zzz_ConsumeStr(s, &index)))
break;
default:
// 判断数字是否符合预期,并且设置当前节点为数字
if (zzz_LIKELY(zzz_ConsumeNum(s, &index)))
break;
}
// 循环解析JSON文本,被构建根节点以外的其它节点
while (zzz_LIKELY(node !=v->N))
{
// 如果父节点是对象,则需要解析Key
if (node->Father->Type==zzz_JSONTYPEOBJECT)
{
// 解析Key和Key后面的:
if (zzz_UNLIKELY(zzz_ConsumeStr(s, &index)==zzz_False))
}
// 获取下一个字符串
c=zzz_Peek(s, &index);
switch (c)
{
case '[':
{
// 解析数组,同上
node->Type=zzz_JSONTYPEARRAY;
struct zzz_Node *n=zzz_AllocatorAlloc(v->A, sizeof(struct zzz_Node));
node->Value.Node=n;
node=n;
continue;
}
case '{':
{
// 解析对象,同上
node->Type=zzz_JSONTYPEOBJECT;
struct zzz_Node *n=zzz_AllocatorAlloc(v->A, sizeof(struct zzz_Node));
node->Value.Node=n;
node=n;
continue;
}
case 'n':
// 解析null,同上
if (zzz_LIKELY(zzz_ConsumeNull(s, &index)))
break;
case 'f':
// 解析false,同上
if (zzz_LIKELY(zzz_ConsumeFalse(s, &index)))
break;
case 't':
// 解析true,同上
if (zzz_LIKELY(zzz_ConsumeTrue(s, &index)))
break;
case '"':
// 解析字符串,同上
if (zzz_LIKELY(zzz_ConsumeStr(s, &index)))
break;
default:
// 解析数字,同上
if (zzz_LIKELY(zzz_ConsumeNum(s, &index)))
break;
}
// 这里是整个算法的关键,回溯
// 如果遇到逗号,则新建一个节点,并把它作为当前节点
// 如果遇到]或者},则当前节点设置为父节点,并且循环以上过程,直到遇到根节点
while (zzz_LIKELY(node !=v->N))
{
if (zzz_LikelyPeekAndConsume(',', s, &index))
{
zzz_Node *n=zzz_AllocatorAlloc(v->A, sizeof(struct zzz_Node));
node->Next=n;
node=n;
break;
}
else
{
char c=zzz_Peek(s, &index);
if (zzz_LIKELY((c=='}' &&
zzz_LIKELY(node->Father->Type==zzz_JSONTYPEOBJECT)) ||
zzz_LIKELY(zzz_LIKELY(c==']') &&
zzz_LIKELY(node->Father->Type==zzz_JSONTYPEARRAY))))
{
node->Next=0;
node=node->Father;
}
else
{
return zzz_False;
}
}
}
}
// 检查是否到达文本结尾
if (zzz_LIKELY(zzz_LikelyPeekAndConsume(0, s, &index)))
{
return zzz_True;
}
return zzz_False;
}反解析函数同理,只是一个相反的过程,详细情况请参考zzz_ValueStringify的实现。
在现代CPU中,为了提高执行的性能,CPU的多个单元会同时执行多条指令。例如当取址单元正在寻找下一条指令前,上一条指令的译码和执行已经在进行中了,这一套机制被称作CPU流水线。条件跳转指令,需要等当前的指令执行完才知道结果并执行跳转,会中断流水线。CPU有一套复杂的分支预测机制,但是我们还是可以在代码层面做一些优化。
分支优化的终极形态是没有分支,但这是不可能的,因此,zzzJSON做分支优化遵循以下两点:
- 减少分支
- 使用__builtin_expect
减少分支
例如在解析JSON文本的时候,zzzJSON会先解析根节点,然后进入循环,解析其它节点,这样在每次循环中可以减少父节点是否存在的判断,具体从代码分析一下:
// ParseFast函数中的主循环逻辑
while (zzz_LIKELY(node !=v->N))
{
// 如果父节点是对象,则需要解析Key
if (node->Father->Type==zzz_JSONTYPEOBJECT)
{
// 解析Key和Key后面的:
if (zzz_UNLIKELY(zzz_ConsumeStr(s, &index)==zzz_False))
}
}如果没有前面先解析父节点的代码,这里只能改成:
do
{
// 如果父节点是对象,则需要解析Key
// 这里必须加上判断父节点是否存在的代码
if (node->Father !=0 && node->Father->Type==zzz_JSONTYPEOBJECT)
{
// 解析Key和Key后面的:
if (zzz_UNLIKELY(zzz_ConsumeStr(s, &index)==zzz_False))
}
}while (zzz_LIKELY(node !=v->N))由于确保了父节点必然存在,因此,减少了大量的判断,提高CPU的执行效率。
使用__builtin_expect
分支是必须的,对于无法去掉的分支,如果我们从逻辑层面能大概率预测其结果,那么我们可以使用__builtin_expect来对我们的代码进行优化。
zzzJSON把__builtin_expect定义为zzz_LIKELY和zzz_UNLIKELY。
当__builtin_expect(x,1)时,编译器会把x为true的代码会作为主流程代码,而x为false的代码为作为支代码,即x为true的代码会被流水线预加载,只有当x为false的时候,流水线才会中断。
当__builtin_expect(x,0)时,编译器会把x为false的代码会作为主流程代码,而x为true的代码为作为支代码,即x为false的代码会被流水线预加载,只有当x为true的时候,流水线才会中断。
zzzJSON中大量使用__builtin_expect,认为绝大多数情况下JSON文本是正确的JSON。例如以下代码:
// 判断字符串是否为正确的字符串
static inline zzz_BOOL zzz_ConsumeStr(const char *s, zzz_SIZE *index)
{
char c;
c=s[(*index)++];
while (zzz_LIKELY(c !=0))
{
// c绝大多数情况下大于0x1f
if (zzz_UNLIKELY((unsigned char)c <=0x1f))
return zzz_False;
// 其它逻辑
}
}由于JSON标准规定,JSON中的字符串不能包含小于或等于0x1f的字符,zzzJSON认为绝大多数情况下,JSON文本是正确的JSON,因此,绝大多数情况下字符串中的字符大于0x1f。
zzzJSON不使用SIMD的是为了平台无关,因为并不是每台机器都支持SIMD的,特别是在大型分布式系统中,老旧机器是必然存在的。但是在某些情况下,可以模拟SIMD,例如下面判断字符串是否为true的代码:
static inline zzz_BOOL zzz_ConsumeTrue(const char *s, zzz_SIZE *index)
{
// 把字符串对应的内容转化为32位无符号整形,然后进行比较
if (zzz_LIKELY(*((uint32_t *)("true"))==*((uint32_t *)(s + *index - 1))))
{
*index +=3;
return zzz_True;
}
return zzz_False;
}在做性能优化之前,必须先把性能测试做好,zzzJSON的性能测试分为两部分:
- 正确性测试
- 速度测试
正确性测试用于保障zzzJSON满足所有JSON标准,速度测试用于证明zzzJSON的解析和序列化速度。

3.2 正确性测试
zzzJSON的正确性测试参考nativejson-benchmark的测试方法,从以下方面进行测试:
- JSON官方网站提供的正确与不正确的JSON样本测试(层数限制那个样本除外);
- 字符串测试;
- 双精度浮点型测试;
- 来回测试(解析后序列化再对比)。
zzzJSON通过以上四个测试,详细的代码在 conformance_test.cpp 文件中。
zzzJSON从多方面测试其解析和序列化速度,主要包括:无数字数据测试、nativejson-benchmark数据测试、淘宝数据测试、混合数据测试、随机长JSON测试和随机短JSON测试,每个测试分别测试解析耗时、序列化耗时和全部耗时,其中全部耗时包括创建对象、解析、序列化和析构的耗时总和,详细的代码在 performance_test.cpp 文件中。以下测试包含了C/C++的主流JSON解析器,其中RapidJSON开启了SIMD。zzzJSON不使用SIMD的主要原因是:1. 不能使用相同的二进制统一部署;2. 增加代码复杂度。
无数字数据测试、nativejson-benchmark数据测试、淘宝数据测试和混合数据测试在每次测试的时候均重启进程,防止命中缓存。随机长JSON测试和随机短JSON测试在同一个进程中进行,可以体现批量处理JSON文本时的性能。
由于zzzJSON使用读时解析,因此,在解析的时候只判断数字的正确性,而不把数字转化成浮点数。大部分JSON解析器都会把数字转化为浮点型,为了保证公平,使用无数字的JSON文本则能够避免这种情况,测试结果如下:
以下所有数据单位为ms。

以上测试表明,在无数字数据测试中,zzzJSON的速度最快。
rapidJSON全部开启了SIMD,其中rapidJSON为默认的rapidJSON,rapidJSONFP为支持全精度的rapidJSON,rapidJSONSTR为把数字解析为字符串的rapidJSON。 由于系统有多个进程在跑,因此,数据会有波动,例如:解析耗时 + 序列化耗时 < 全部耗时。但是上表反映的情况基本符合客观事实,多次重跑结果大致相同。 ArduinoJSON和parsonJSON不参与无数字数据测试是因为他们解析长JSON时会发生错误。
nativejson-benchmark在JSON性能测试方面做了非常大的贡献,因此,使用nativejson-benchmark的数据进行测试非常有意义,测试结果如下:
以下所有数据单位为ms。
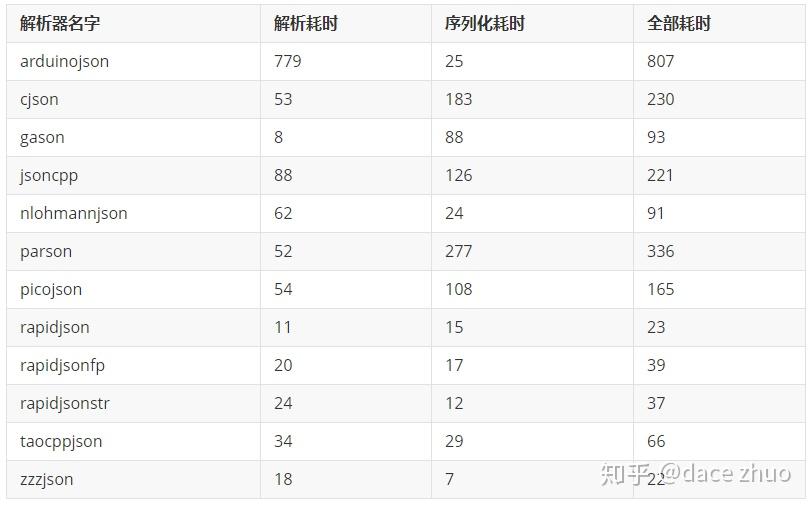
以上测试表明,在nativejson-benchmark数据测试中,zzzJSON的速度最快。
使用fastjson提供的淘宝网的真实数据进行测试,能够更好的体现真实的使用情况,测试结果如下:
以下所有数据单位为ms。
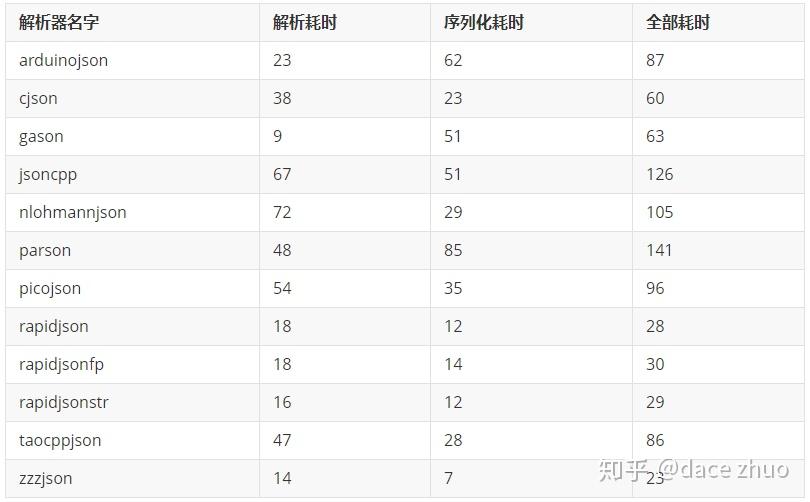
以上测试表明,在淘宝数据测试中,zzzJSON的速度最快。
以下所有数据单位为ms。
混合数据测试使用了nativejson-benchmark、淘宝和json-iterator的数据,能够更好的体现真实的使用情况,测试结果如下:
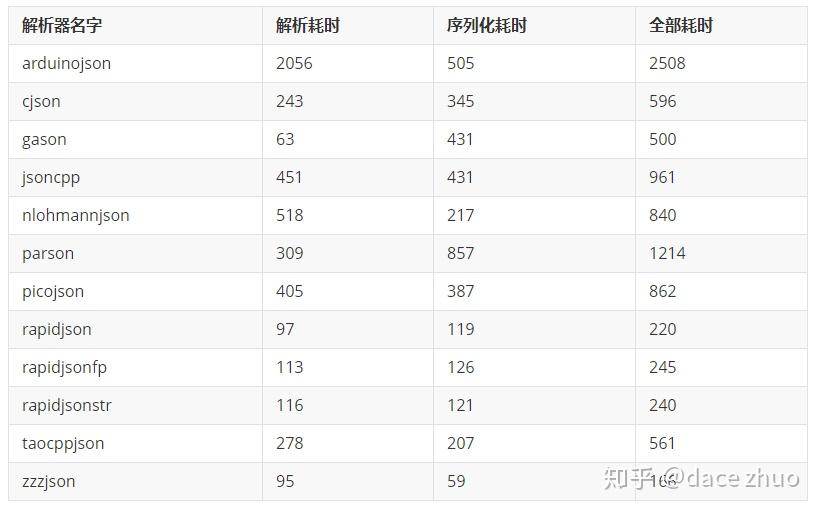
以上测试表明,在混合数据测试中,zzzJSON的速度最快。
该测试随机生成一万条短JSON用于测试,该测试用于检验批量处理JSON的性能,测试结果如下:
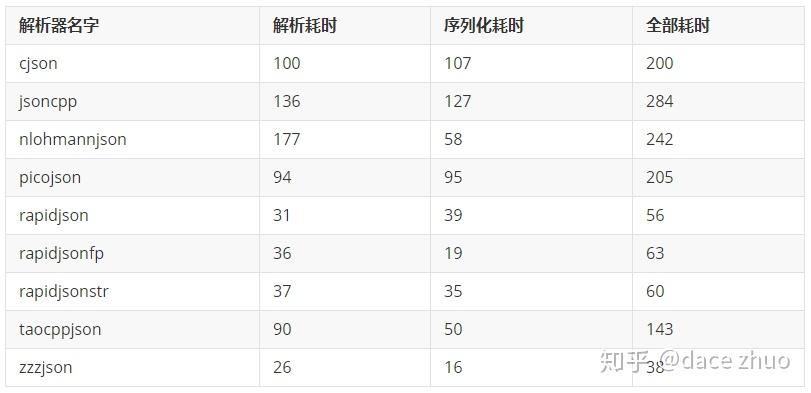
以上测试结果表明,在批量处理短JSON的场景,zzzJSON的速度最快。
该测试随机生成一百条长JSON用于测试,该测试用于检验批量处理JSON的性能,测试结果如下:
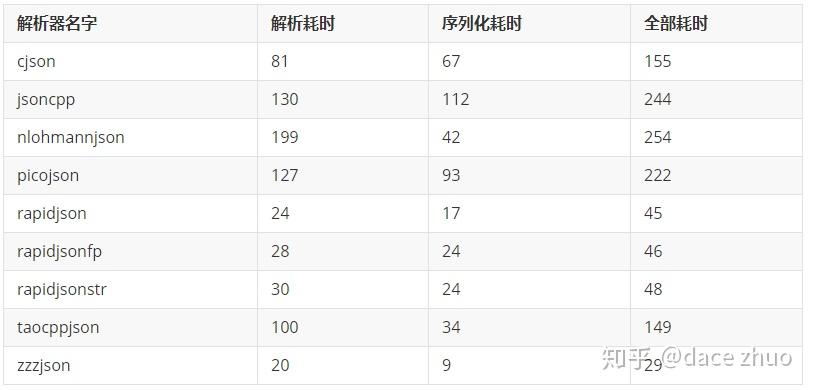
以上测试结果表明,在批量处理长JSON的场景,zzzJSON的速度最快。
测试结果表明,在主流JSON解析库中,zzzJSON拥有最快的解析和序列化速度。
- zzzJSON 高性能JSON解析库 https://github.com/dacez/zzzjson 求赏个星啦
- zzzperformance 性能优化的艺术和实践 https://github.com/dacez/zzzperformance 求赏个星啦
本人是微信一枚高级中级攻城狮,最近半年一直在做架构与性能优化,取得一些成果,与大家分享,若有错误,轻喷。
纯兴趣爱好,无它。
若对大规模分布式系统架构与性能优化有兴趣,欢迎交流。
感谢美美的老婆为我设计了一个酷酷的图标,也感谢她支持我完成zzzJSON的编写。
不给点福利哪里来赞~~







